Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities
Related Articles: Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities
Introduction
With great pleasure, we will explore the intriguing topic related to Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities
- 2 Introduction
- 3 Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities
- 3.1 Understanding Delta Lake: A Data Lake Management Solution
- 3.2 Benefits of Delta Lake: A Comprehensive Overview
- 3.3 Practical Applications of Delta Lake: Real-World Use Cases
- 3.4 FAQs: Addressing Common Questions about Delta Lake
- 3.5 Tips for Utilizing Delta Lake Effectively
- 3.6 Conclusion: Embracing the Future of Data Management with Delta Lake
- 4 Closure
Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities

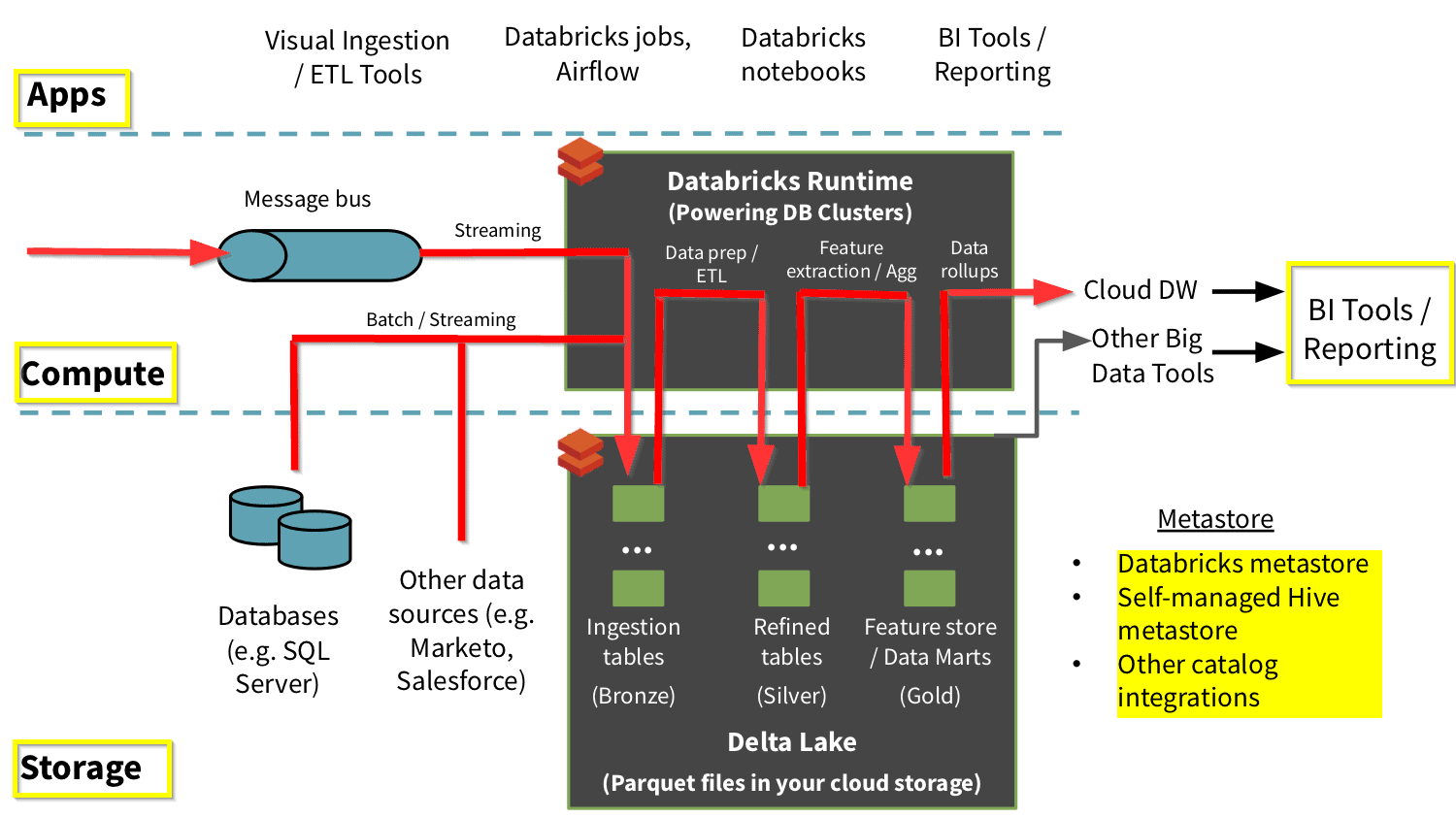
The landscape of data management is constantly evolving, driven by the exponential growth of data and the increasing demand for real-time insights. This dynamic environment has spurred the development of innovative technologies, with Delta Lake emerging as a powerful solution for managing data in a reliable, scalable, and efficient manner.
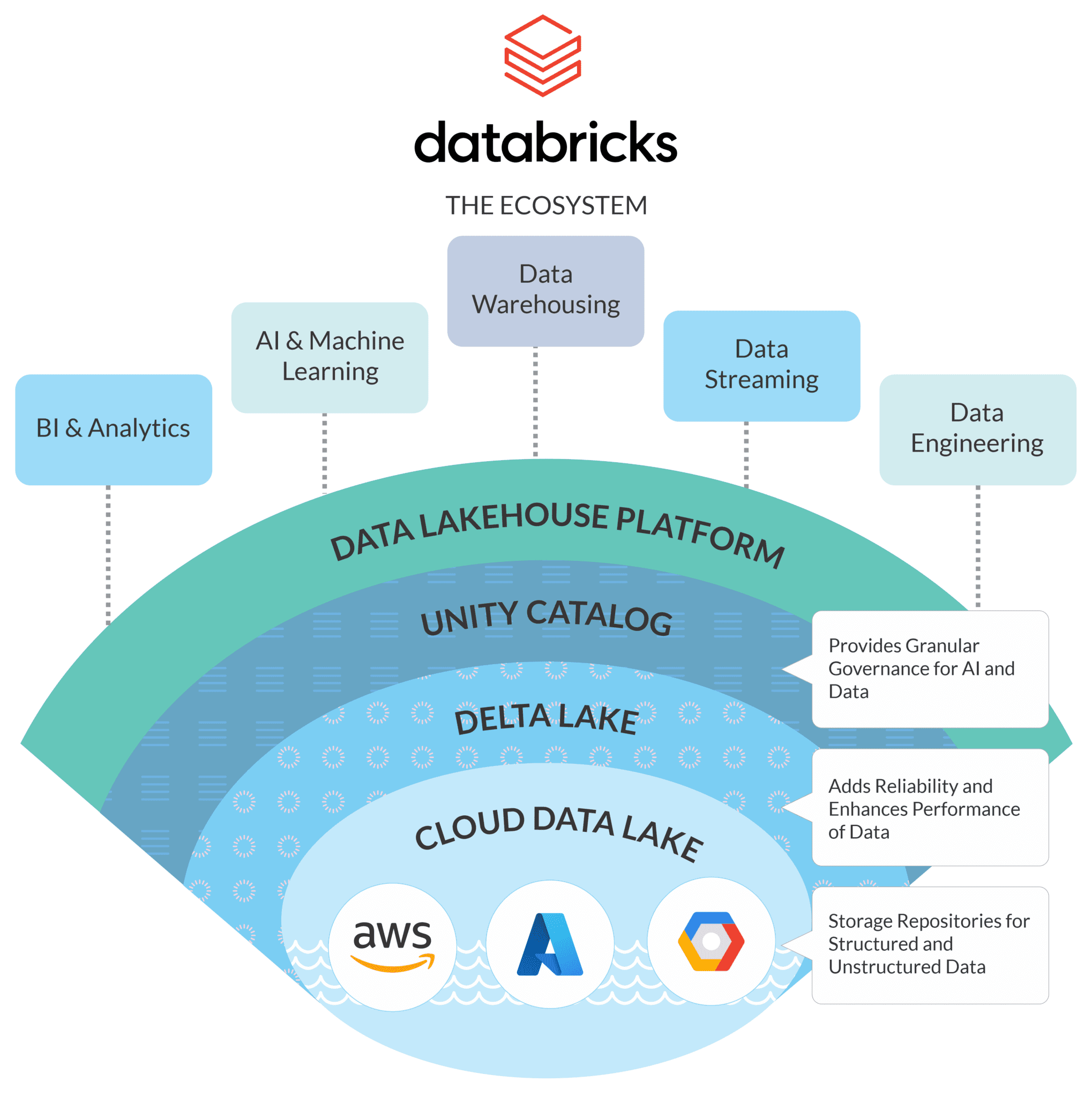
Delta Lake, built upon the Apache Spark ecosystem, provides a robust framework for data lakes, offering a unified approach to managing data across diverse sources and formats. This article delves into the intricacies of Delta Lake, exploring its core features, benefits, and practical applications.
Understanding Delta Lake: A Data Lake Management Solution
Delta Lake stands out as a unified data management solution for data lakes, addressing key challenges faced by traditional data lake implementations. It achieves this by introducing a series of innovative features:
-
Transactionality and ACID Compliance: Delta Lake ensures data integrity through its transactional capabilities, guaranteeing atomicity, consistency, isolation, and durability (ACID) properties. This ensures that data modifications occur reliably and consistently, regardless of the scale or complexity of operations.
-
Schema Enforcement: Delta Lake enforces schema evolution, ensuring that data conforms to defined schemas. This feature facilitates data consistency and simplifies data processing, enabling efficient data integration and analysis.
-
Data Versioning and Time Travel: Delta Lake tracks changes to data, allowing users to revert to previous versions or examine historical data snapshots. This capability provides a powerful mechanism for auditing, data recovery, and exploring data trends over time.
-
Scalability and Performance: Delta Lake leverages the distributed processing capabilities of Apache Spark, enabling efficient data processing on large-scale datasets. Its optimized storage and query execution mechanisms contribute to enhanced performance and scalability.
-
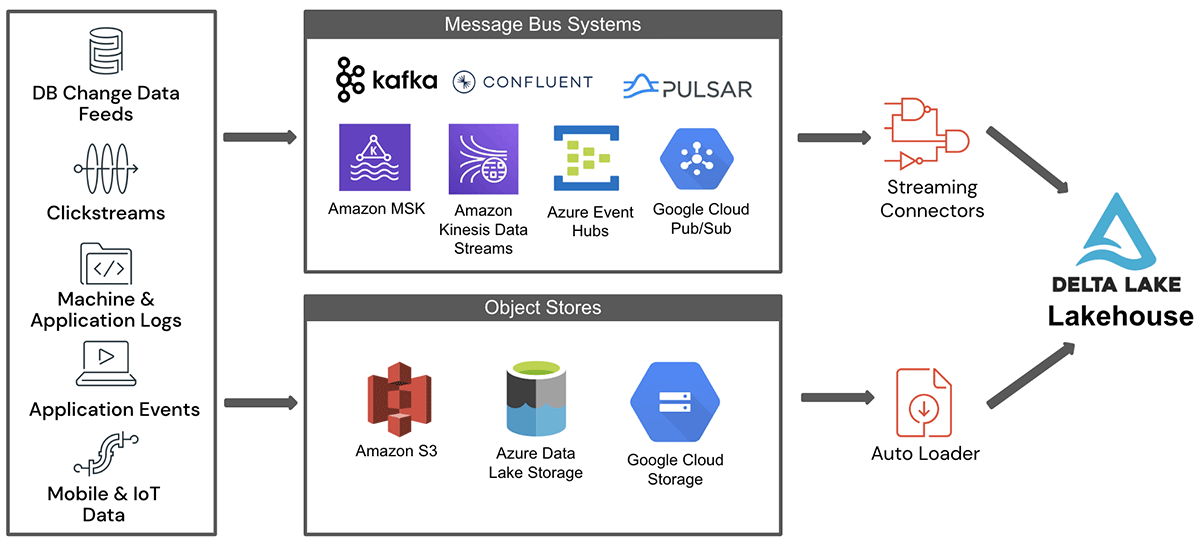
Data Integration and Interoperability: Delta Lake seamlessly integrates with various data sources and formats, including Apache Parquet, Avro, JSON, and ORC. This facilitates a unified approach to data management, regardless of the origin or format of the data.
Benefits of Delta Lake: A Comprehensive Overview
The comprehensive features of Delta Lake translate into a multitude of benefits for organizations seeking to optimize their data management strategies:
-
Enhanced Data Quality and Integrity: Delta Lake’s transactional capabilities ensure data consistency and reliability, eliminating data corruption and inconsistencies, leading to higher data quality.
-
Streamlined Data Pipelines: The ability to manage data across diverse sources and formats within a unified framework simplifies data pipelines, reducing complexity and improving efficiency.
-
Improved Data Governance: Schema enforcement and data versioning provide powerful tools for data governance, enabling organizations to track changes, enforce data quality standards, and ensure data compliance.
-
Enhanced Data Analytics Capabilities: Delta Lake’s data management features facilitate efficient data processing and analysis, enabling organizations to extract valuable insights from their data more effectively.
-
Scalability and Flexibility: Delta Lake’s scalable architecture and support for diverse data sources and formats provide flexibility and adaptability to meet the evolving needs of modern data-driven organizations.
Practical Applications of Delta Lake: Real-World Use Cases
Delta Lake finds applications across diverse domains, empowering organizations to leverage data effectively:
-
Data Warehousing and Analytics: Delta Lake serves as a robust foundation for data warehousing, enabling organizations to efficiently load, transform, and analyze large datasets for business intelligence and decision-making.
-
Machine Learning and AI: Delta Lake’s data management capabilities are crucial for machine learning and AI applications, facilitating the efficient processing and analysis of large datasets for model training and prediction.
-
Data Streaming and Real-Time Analytics: Delta Lake integrates seamlessly with streaming data sources, enabling real-time data ingestion, processing, and analysis, supporting applications like fraud detection, anomaly detection, and event monitoring.
-
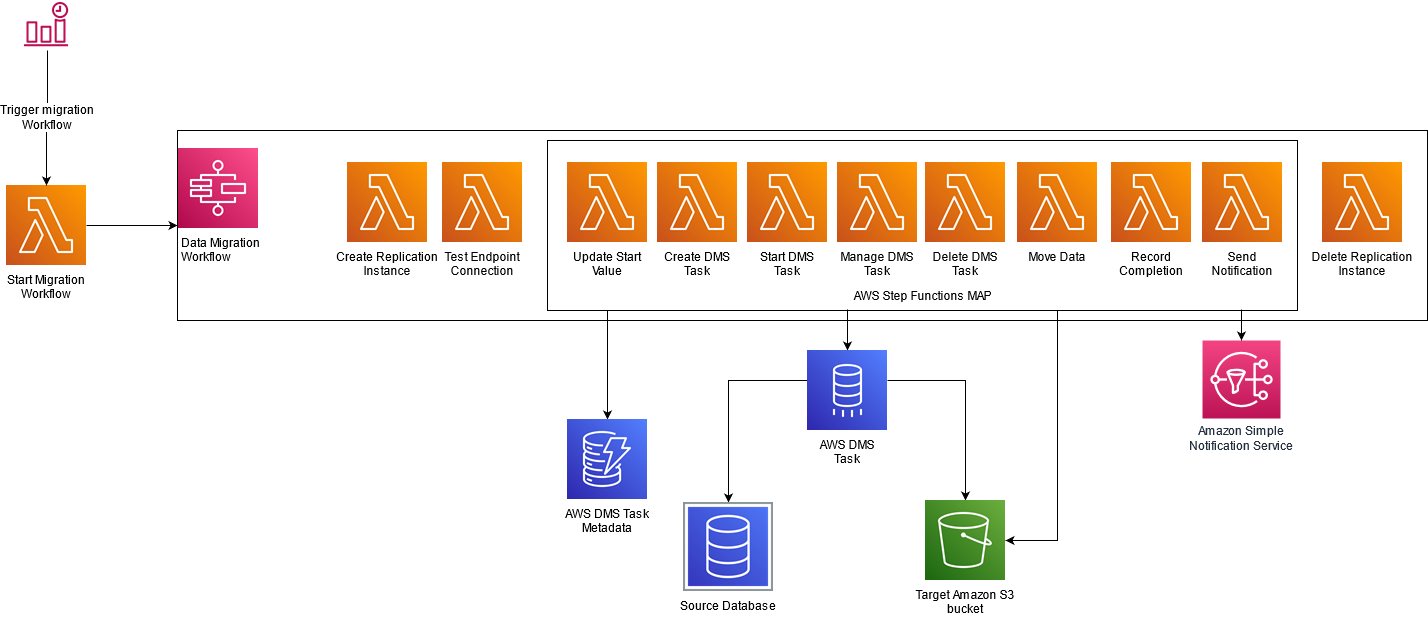
Data Lake Modernization: Delta Lake provides a path for modernizing existing data lakes, enhancing data quality, governance, and performance, while ensuring compatibility with existing data assets.
FAQs: Addressing Common Questions about Delta Lake
Q: What are the key differences between Delta Lake and traditional data lakes?
A: Traditional data lakes often lack transactional capabilities, schema enforcement, and versioning features, leading to data inconsistencies, governance challenges, and difficulties in managing complex data pipelines. Delta Lake addresses these limitations by providing a robust framework for managing data lakes with ACID properties, schema evolution, and data versioning.
Q: How does Delta Lake integrate with Apache Spark?
A: Delta Lake is built on top of Apache Spark, leveraging its distributed processing capabilities for efficient data processing and analysis. Delta Lake integrates seamlessly with Spark, providing a unified framework for data management and analysis within the Spark ecosystem.
Q: Is Delta Lake open source?
A: Yes, Delta Lake is an open-source project, fostering collaboration and innovation within the data management community. This open-source nature ensures transparency, community engagement, and a wide range of contributions.
Q: What are the benefits of using Delta Lake for data warehousing?
A: Delta Lake provides a robust foundation for data warehousing, offering ACID properties, schema enforcement, and data versioning, ensuring data quality, consistency, and governance. Its integration with Spark enables efficient data loading, transformation, and analysis for business intelligence and decision-making.
Q: Can Delta Lake be used for data streaming applications?
A: Yes, Delta Lake integrates seamlessly with streaming data sources, enabling real-time data ingestion, processing, and analysis. This supports applications like fraud detection, anomaly detection, and event monitoring.
Tips for Utilizing Delta Lake Effectively
-
Start with a clear data management strategy: Define data requirements, use cases, and governance policies before implementing Delta Lake.
-
Optimize data schema design: Carefully define data schemas to ensure data consistency, efficiency, and scalability.
-
Leverage Delta Lake’s transactional capabilities: Utilize Delta Lake’s ACID properties to ensure data integrity and reliability in data pipelines.
-
Explore Delta Lake’s data versioning features: Utilize data versioning for auditing, data recovery, and exploring data trends over time.
-
Integrate Delta Lake with existing data infrastructure: Seamlessly integrate Delta Lake with existing data sources, tools, and applications to leverage its benefits.
Conclusion: Embracing the Future of Data Management with Delta Lake
Delta Lake emerges as a transformative solution for data management in the modern data landscape. Its robust features, including transactional capabilities, schema enforcement, data versioning, scalability, and integration with Apache Spark, provide a comprehensive framework for managing data across diverse sources and formats. By embracing Delta Lake, organizations can enhance data quality, streamline data pipelines, improve data governance, and unlock the full potential of their data assets for business intelligence, machine learning, and real-time analytics. As data continues to grow exponentially, Delta Lake stands as a powerful tool for navigating the complexities of data management and harnessing the insights that drive innovation and growth.




Closure
Thus, we hope this article has provided valuable insights into Navigating the Complexities of Data: A Deep Dive into Delta Lake’s Data Management Capabilities. We appreciate your attention to our article. See you in our next article!